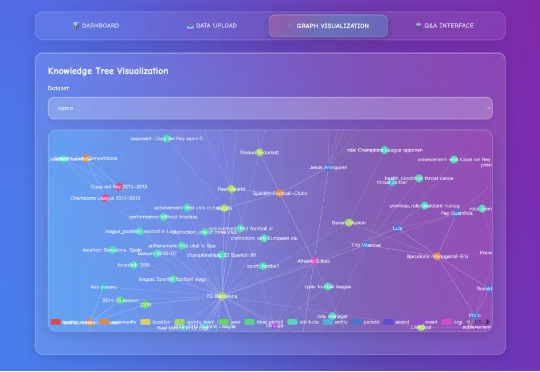
腾讯优图重磅开源Youtu-GraphRAG,实现图检索增强技术新突破
腾讯优图重磅开源Youtu-GraphRAG,实现图检索增强技术新突破图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗
来自主题: AI技术研报
9914 点击 2025-09-14 10:45
 搜索
搜索
图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗
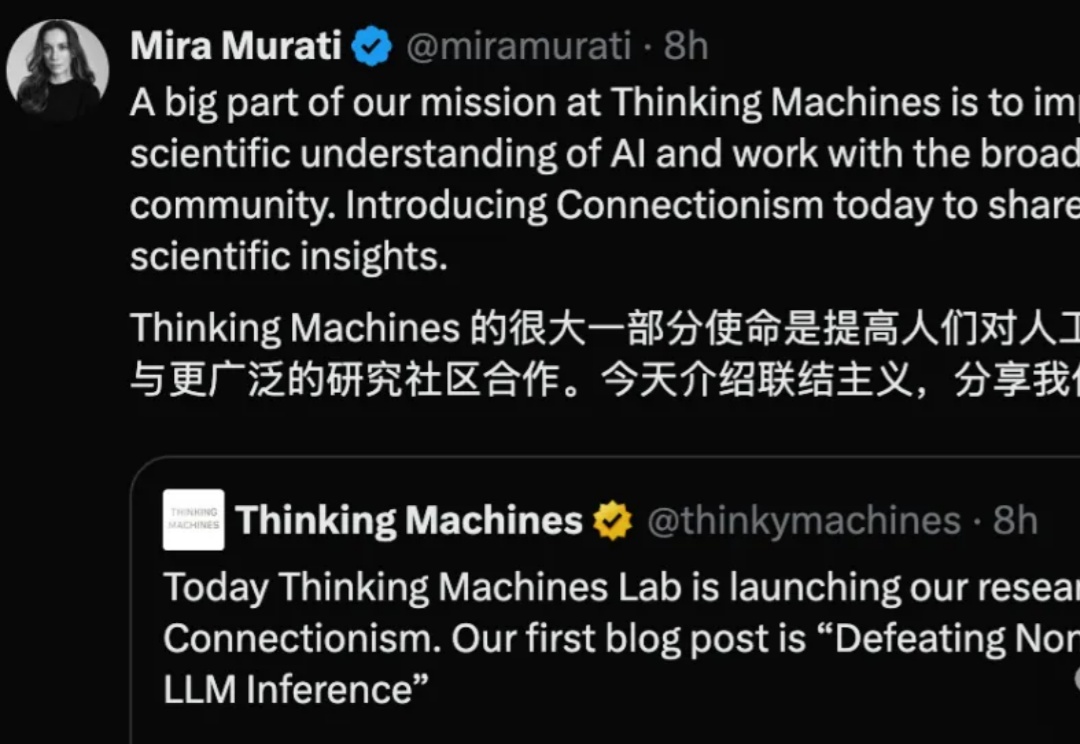
刚刚,0产出估值就已冲破120亿美元的Thinking Machines,终于发布首篇研究博客。
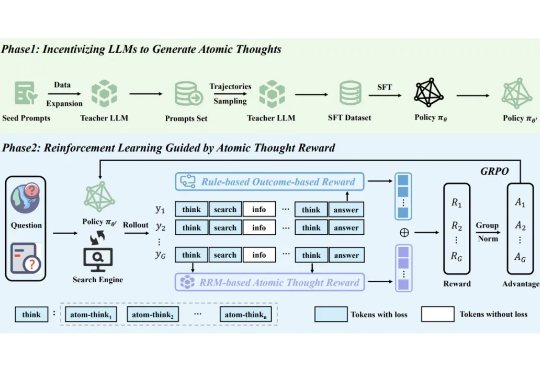
尽管 LLM 的能力与日俱增,但其在复杂任务上的表现仍受限于静态的内部知识。为从根本上解决这一限制,突破 AI 能力界限,业界研究者们提出了 Agentic Deep Research 系统,在该系统中基于 LLM 的 Agent 通过自主推理、调用搜索引擎和迭代地整合信息来给出全面、有深度且正确性有保障的解决方案。
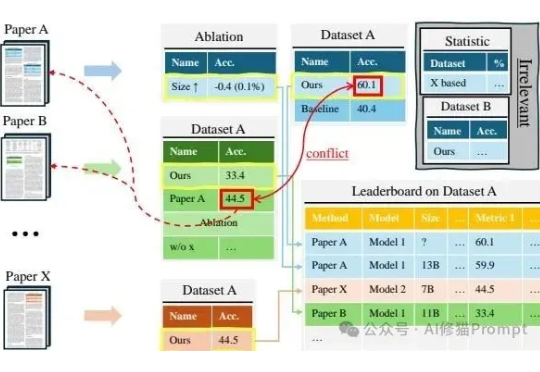
您可能已经在产品里放进了问答、总结、甚至自动报表模块,但表格一上来,体验就变味了,这不奇怪。表格是二维、带结构、还经常跨表跨文,和纯文本完全不一样;项目作者在《Tabular Data Understanding with LLMs》里把这件事掰开揉碎,从输入表示到任务版图,再到评测与未来方向都梳理清楚了。
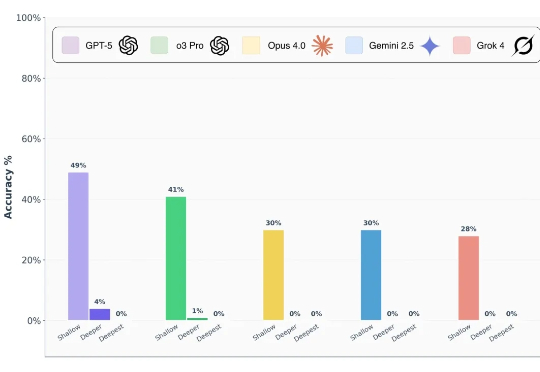
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。
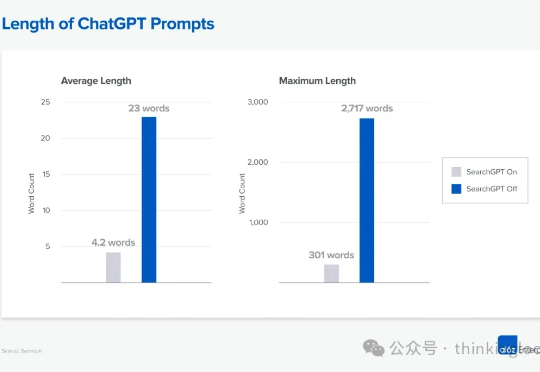
GEO/AEO,并不是一个全新的概念。简单说来,就是 AI 搜索和 LLM 时代的 SEO。
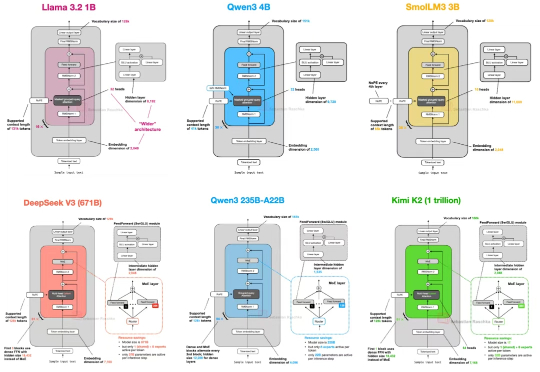
自首次提出 GPT 架构以来,转眼已经过去了七年。 如果从 2019 年的 GPT-2 出发,回顾至 2024–2025 年的 DeepSeek-V3 和 LLaMA 4,不难发现一个有趣的现象:尽管模型能力不断提升,但其整体架构在这七年中保持了高度一致。
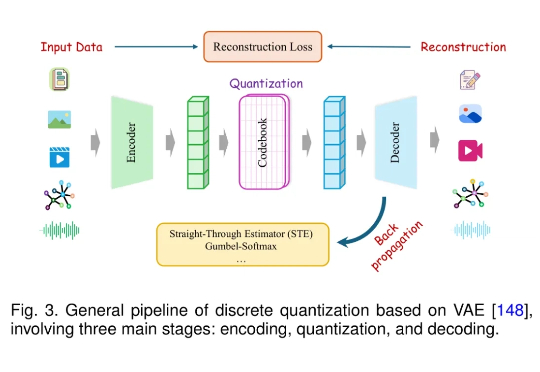
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
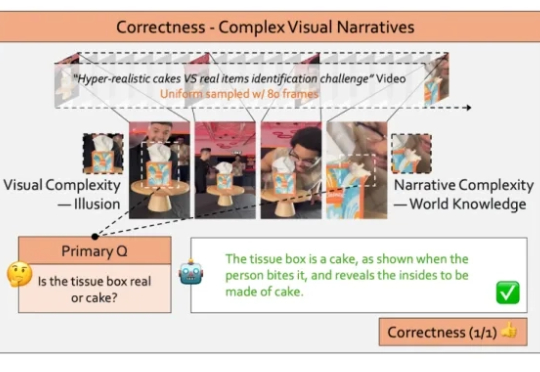
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。